Uber Engineering
Under the Hood: Scaling Responsible AI at Uber
Wonder how Uber scales responsible AI at a massive scale? Dive into Uber’s centralized Model Catalog, automated explainability, and governance built directly into the engineering workflow.
Accelerating Deep Learning: How Uber Optimized Petastorm for High-Throughput and Reproducible GPU Training

Explore how we optimized Petastorm to cut deep learning training time by 6× and eliminated hidden randomness at Uber.
AI Prototyping Is Changing How We Build Products at Uber

Uber
How Uber Executed A JUnit Migration at Massive Scale

Large-scale test migrations aren't impossible—they're automatable. Discover how Uber pulled off one of the largest JUnit migrations ever, transforming over 1.25 million lines of test code in just a few months.
How Uber Built an Agentic System to Automate Design Specs in Minutes

Uber is setting a new standard for design systems by using the Figma Console MCP to shatter the manual documentation bottleneck. By letting AI agents pull directly from design data, weeks of spec writing turns into minutes of automated precision.
Transforming Ads Personalization with Sequential Modeling and Hetero-MMoE at Uber

Learn how we rebuilt our Ads personalization model with Transformer-based sequential encoders and HeteroMoE to better capture user intent, boost targeting accuracy, and scale intelligent ads delivery across the platform.
Building High Throughput Payment Account Processing

Uber’s Payment Account Batch Processing system handles over 30 financial update operations per second for hot accounts with sub-second batching and strict consistency. Learn how we built it without using special hardware or software.
Superuser Gateway: Guardrails for Privileged Command Execution

Database Federation: Decentralized and ACL-Compliant Hive™ Databases
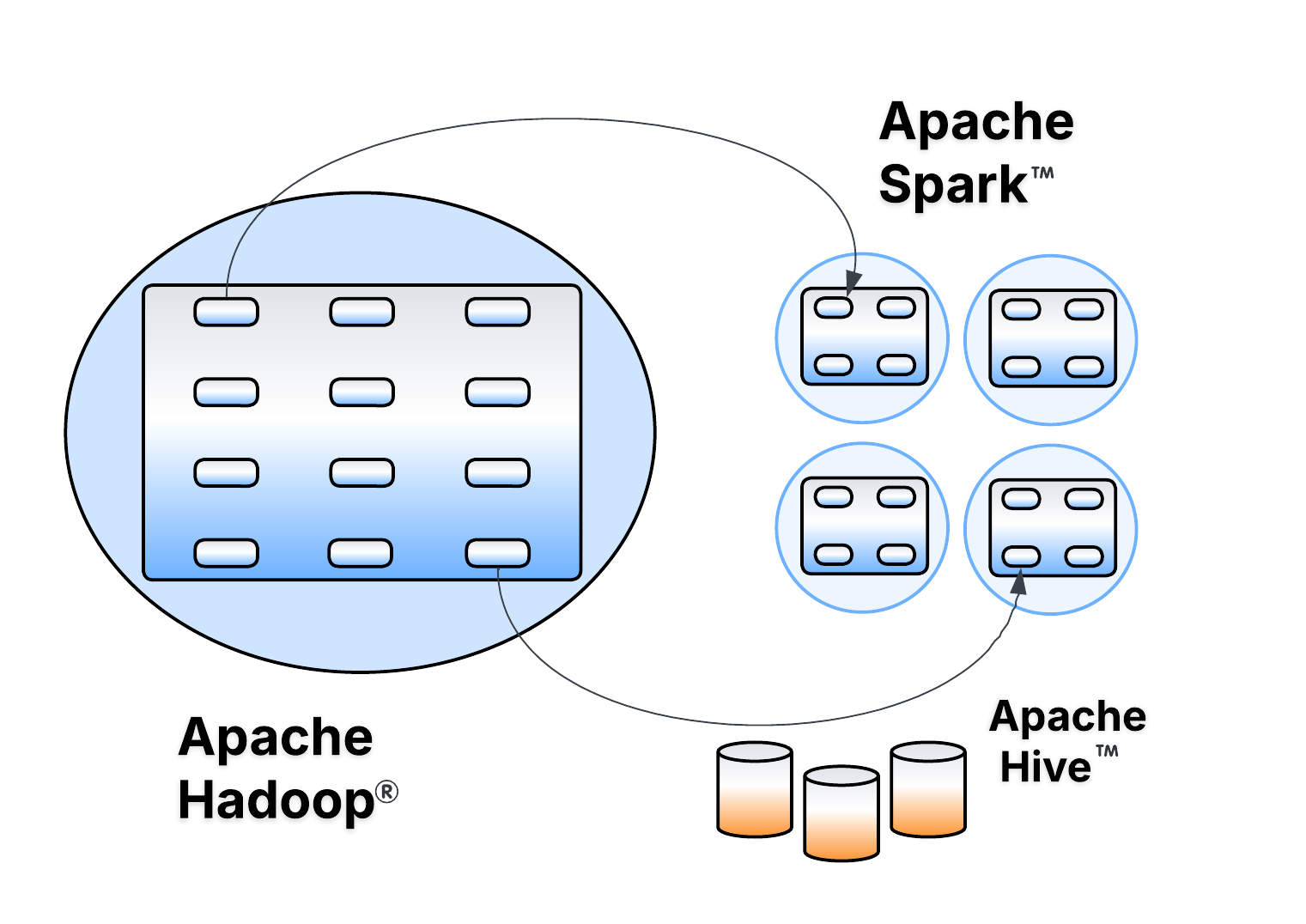
Uber’s 10PB, 16K-dataset Hive monolith for the Delivery business had huge limitations. See how we transformed it into a secure, scalable, decentralized platform with zero downtime and saved more than 1PB along the way. #BigData #DataSecurity
Uber’s Rate Limiting System

Discover how Uber built and automated a global rate-limiting system that protects millions of RPCs per second, improving reliability, reducing latency, and simplifying operations across our service mesh.
Introducing uFowarder: The Consumer Proxy for Kafka Async Queuing

Uber processes trillions of Kafka messages per day on a push-based consumer proxy in real time. Read this blog to learn about the thinking behind open source uForwarder before applying it to your use cases.
How Uber Scaled Data Replication to Move Petabytes Every Day

Uber prioritizes a reliable data lake, which is distributed across on-premise and cloud environments. This multi-region setup presents challenges for ensuring reliable and timely data access due to limited network bandwidth and the need for seamless data availability, particularly for disaster recovery. Uber uses the Hive Sync service, which uses Apache HadoopⓇ Ditscp (Distributed Copy) for data replication. However, with Uber’s Data Lake exceeding 350 PB, Distcp’s limitations became apparent. This blog explores the optimizations made to Distcp to enhance its performance and meet Uber’s growing data replication and disaster recovery needs across its distributed infrastructure.